This is a companion piece to our ICLR paper Learning is Forgetting: LLM Training As Lossy Compression. Also available as a webpage here
somewhere on your phone right now there’s a photo that takes up about 3 megabytes. if you’d taken the same photo as a raw bitmap — every pixel’s red, green, and blue values written out directly — it would be closer to 25 megabytes. the jpeg is eight times smaller and, unless you go looking for it, you can’t tell the difference.
this is lossy compression. and once you understand how it works, you start to see it everywhere.
morse code compresses a 26 character alphabet into just two symbols: dot and dash. giant clams visual system compresses the world around it into just two categories movement, and no movement - so they can slam shut if a predator swims by. vervet monkeys compress the world into three categories: eagle, snake, and leopard — so they can give a single alarm call that tells everyone else which one is coming.
consider yourself. i don’t know about you but i can’t remember my entire life. at this moment, typing – at my laptop, i do not have to hand a lossless record of every conversation i’ve had, every book i’ve read, or everyone i’ve ever sat across from at dinner. i can recall the important moments with real precision, standing in my high-school’s orchestra room when i found out i got into university, flying home from the UK to surprise my mum for her 60th birthday - the look on her face as i walked through the door. most things though i just remember the shape of: i know i love my friends from undergrad, but i would be hard pressed to try and recall all the moments that made mel, or celia, or pedro so important to me - those relationships have been abstracted into a certain kind of warmth, regardless of the exact details. as i age and think about some parts of my life less they become more and more abstract, until they’re just a feeling (edinburgh:beatiful, nostalgic, formative; summer camp:nostalgic, formative; high school:formative).
who i am is not a catalog of the things that have happened to me, but the way i choose to compress them. the sets of categories i sort my experiences into as i daily confront the reality that i can’t remember each of them in toto. as i develop the abstractions i compress my life into i define myself - deciding what information from each moment is relevant, and forgetting the rest. in the process i develop a semantics that not only describes my life but how i am able to understand the world around me. compression groups similar things together to save space, and day by day i relate what is happening now to similar moments that have happened before as i abstract each moment into the concepts i’ve come to readily compress my reality into.
compression isn’t just a way to save space. it’s a fundamental principle of how we learn and understand the world. so much of our intelligence is the ability to relate new problems we’re asked to solve to problems we’ve solved before — compressing our experience into a form that retains the information we need to achieve our goals, while discarding the rest. it’s how we make sense of the world, and how we make predictions about it.
llms are trained on the entire internet. the raw data is trillions of words or tens of terabytes. yet the resulting model is on the order of gigabytes. despite this it proves able to recall specific facts from specific web pages, generate fluent prose on virtually any topic, and answer questions it hasn’t explicitly seen before. the abiliy to approximately reconstruct the original training data, and to generalise beyond it are ultimately the result of lossy compression.
here we discuss this idea at a high level - what compression is, how it works, and how it gives rise to generalisations (for more detail and emiprical results showing how models lean an optimal compression of the internet refer to our iclr 2026 paper). first we’ll introduce the core concepts of compression before considering llms. to be clear thinking of a model like an LLM as a compression of its training data isn’t new — it’s implicit in the very idea of a “model” — but we are the first to be able to quantitatively show that this is what’s actually happening during LLM pre-training, and to explore the implications of this perspective for understanding how and why these models learn to generalise.
lossless vs. lossy
there are two broad families of compression.
lossless compression finds redundancy in data and encodes it more efficiently, but preserves everything. zip files, png images, lossless audio — you can decompress them and recover the original byte-for-byte. nothing is gone.
lossy compression goes further. it throws some information away, permanently, in exchange for a much smaller representation. jpegs, mp3s, most video you’ve ever watched — none of these can fully reconstruct their source. what comes back is a close approximation, not the original.
in the lossy case the key question is: which information do you throw away?
a jpeg discards fine-grained colour variation at high spatial frequencies — subtle shifts in hue across a smooth patch of sky. your visual system isn’t very sensitive to these anyway, so you don’t notice. an mp3 discards sound at frequencies outside normal human hearing, and quieter sounds that would be “masked” by louder ones happening at the same time. your auditory system would never have caught them either.
in both cases, the compression is opinionated about the receiver (Jayant, Johnston, and Safranek 1993). it works because there’s a known audience — a human eye, a human ear — with finite precision. the codec is designed around those limitations. throw away what doesn’t matter for the receiver, keep what does.
this is the core idea, lossy compression saves space by preserving only the information that’s needed for a goal.
| codec | input | goal | forgets |
|---|---|---|---|
| mp3 | raw audio | sounds nice to humans | frequencies outside human hearing |
| jpeg | raw image data | looks nice to humans | subtle colour variations |
| llm | the entire internet | generate responses humans prefer | ? |
compression enables generalisation
but compression isn’t just about saving space. it’s the reason why a model like an llm can generalise so well to so many tasks.
a lossless format memorises. like a lookup table it keeps everything — every quirk of this specific file, every idiosyncrasy of this particular recording. the representation is an exact copy, which means things that are similar in the world aren’t necessarily similar in the representation. two slightly different recordings of the same song might share almost no bits.
a lossy format is forced to abstract. by throwing away detail that isn’t load-bearing, it maps the raw input into a smaller space where functionally similar things end up close together. the compression creates similarity structure.
the cognitive scientist roger shepard observed in the 1950s that generalisation follows a remarkably consistent pattern: the probability that two things are treated as equivalent decays exponentially with their distance in representational space (Shepard 1957, 1987). this isn’t a quirk of any particular domain — it’s a near-universal law of how semantic representations generalise, later given a rational bayesian justification by tenenbaum and griffiths (Tenenbaum and Griffiths 2001). the implication being that generalisation behaviour is a function of representational geometry. the way you lay out your abstract concepts determines how you generalise .
lossy compression directly shapes that geometry. by discarding idiosyncratic detail and keeping structure that’s relevant to the goal, it pushes things that are functionally similar together, and pulls things that are functionally different apart. exemplar models of categorisation formalised this relationship, showing that generalisation to novel items depends on their similarity to stored instances (Medin and Schaffer 1978; Nosofsky 1986; Kruschke 1992), while prototype effects demonstrated that representations encode central tendencies that support interpolation to never-seen items (Posner and Keele 1968).
the theoretical endpoint of this argument, made explicitly by edelman and later by gärdenfors, is that semantic representations simply are similarity structures — that what a representation does is define a geometry, and that cognitive operations reduce to computations over that geometry (Edelman 1998; Gärdenfors 2000; Kriegeskorte and Kievit 2013).
so the somewhat more profound reason mp3s work isn’t just that they save space. it’s that by discarding what doesn’t matter for human hearing, they produce a representation where similar-sounding things end up close together in the compressed space. that structure is what lets you still recognise the song — not from a perfect copy, but from a compressed version that preserved the geometry of the original that matters. a good lossy compression is one where the similarity structure in the compressed space faithfully mirrors the similarity structure in the source. similar meanings are represented by similar forms
rate-distortion theory & the information bottleneck
information theory gives this a formal shape (Shannon 1948). the problem is called rate-distortion theory: you want to represent some source using as few bits as possible (the rate), while achieving a particular error rate (the distortion).
the information bottleneck (Tishby, Pereira, and Bialek 2000) uses a mutual information to measure how much information a compression has about the input source (complexity), and about the goal or output (expressivity). compress the input, but only discard information that doesn’t help predict the target. anything that doesn’t help is irrelevant by definition — throw it away.
what survives is a representation organised around the task. things that play the same predictive role end up in the same place. the compression doesn’t just make things smaller — it organises them.
you can visualise this on an information plane: one axis measures how much the representation retains about the input (complexity), the other how much it retains about the output (expressivity). every compression scheme lives somewhere on this plane.
consider three different models that represent three different examples as coloured bitmaps:
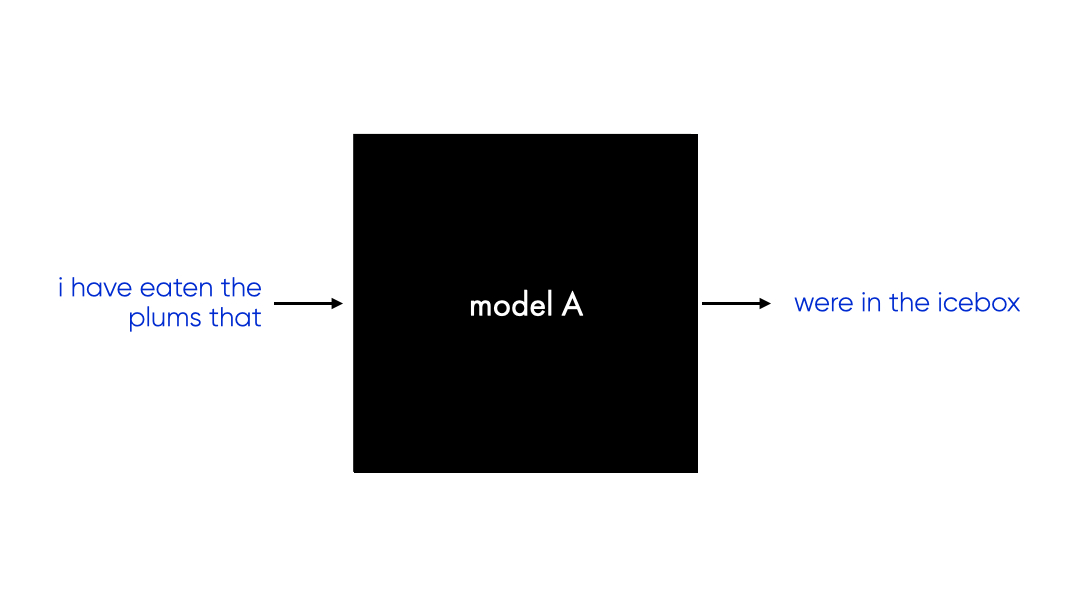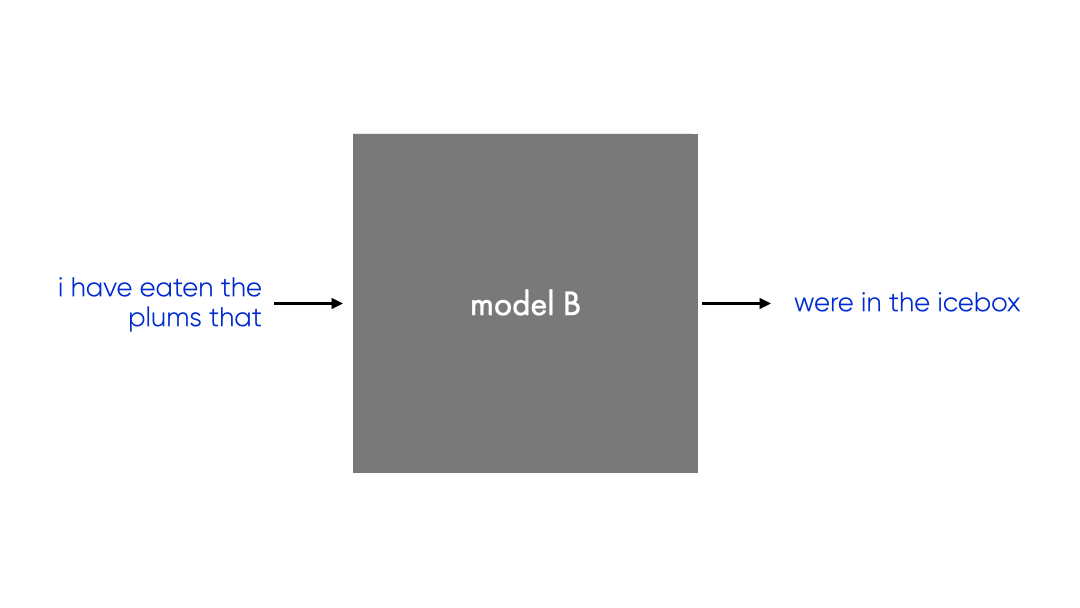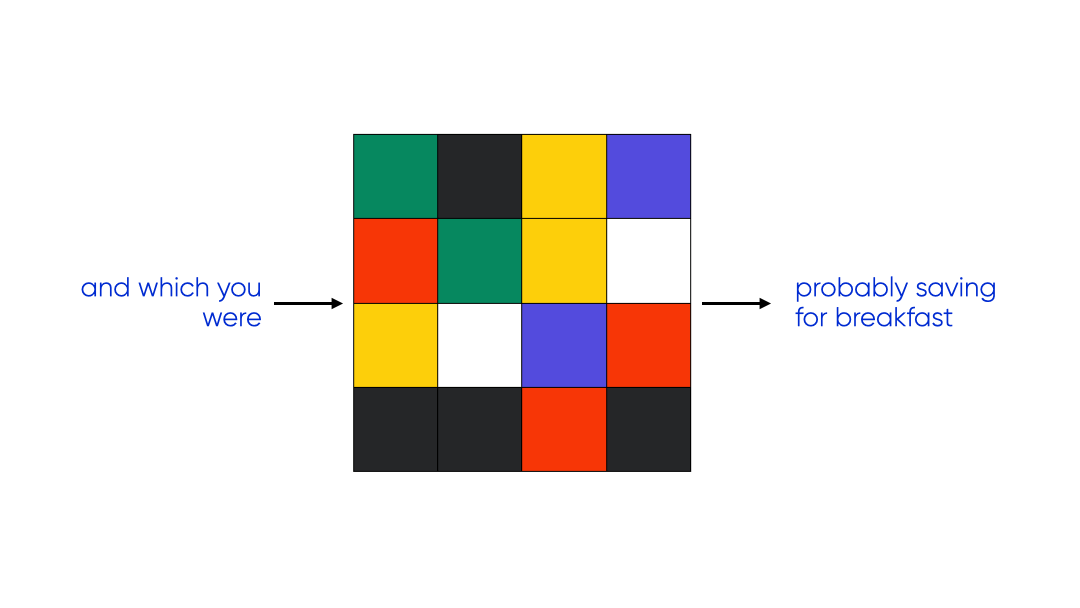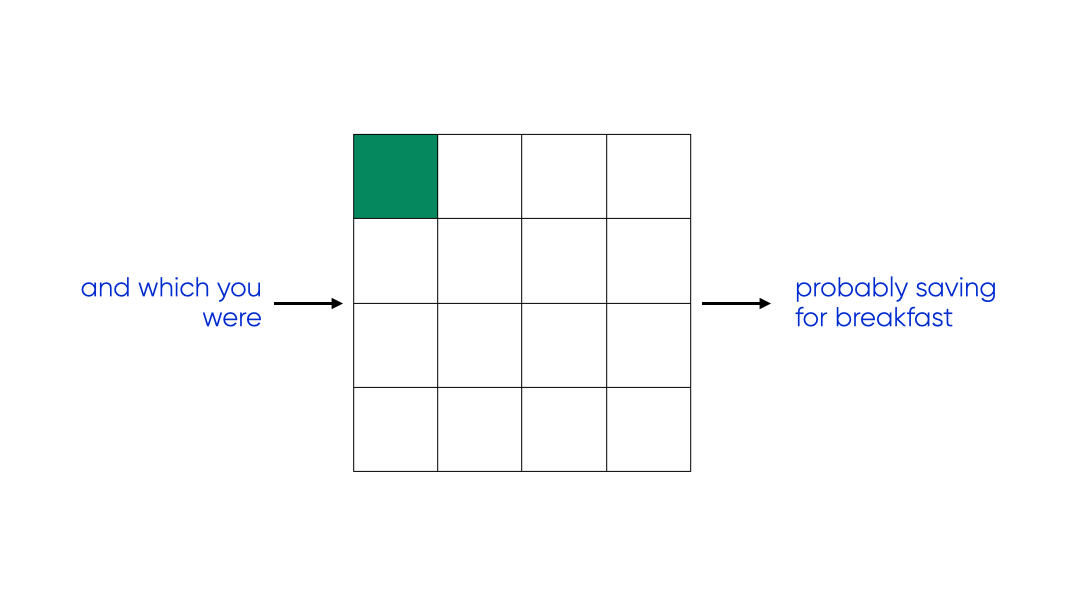
We can look at this as three different compression schemes:
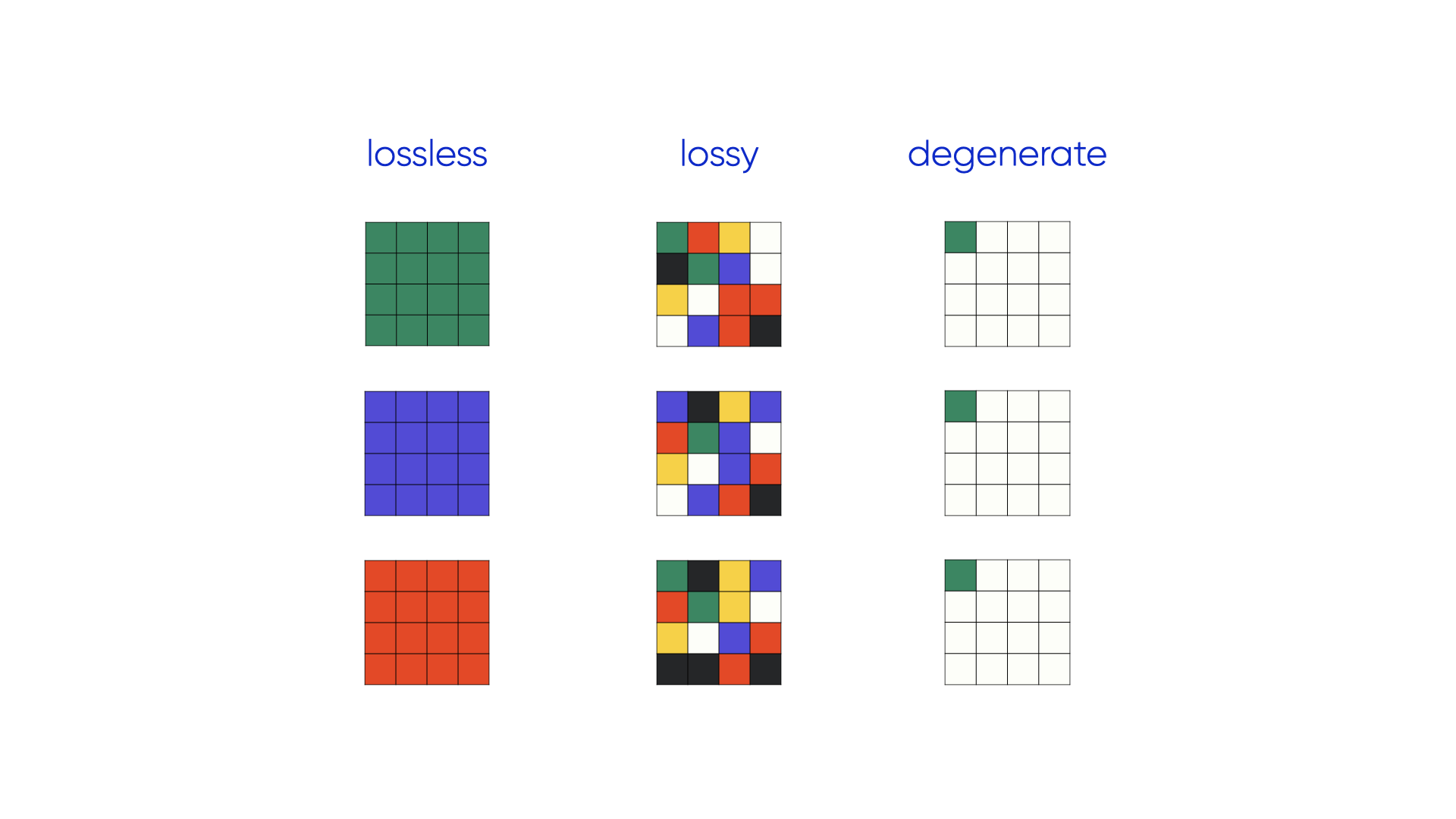
plotted on the information plane a lossless compression maxmises expressivity at the cost of complexity. a good lossy compression sits close to the information bottleneck bound — it throws away as much as possible while keeping information about the goal (expressivity) high. a suboptimal compression has the complexity of the lossless case but much lower expressivity — it preseerves information that isn’t needed for the task.
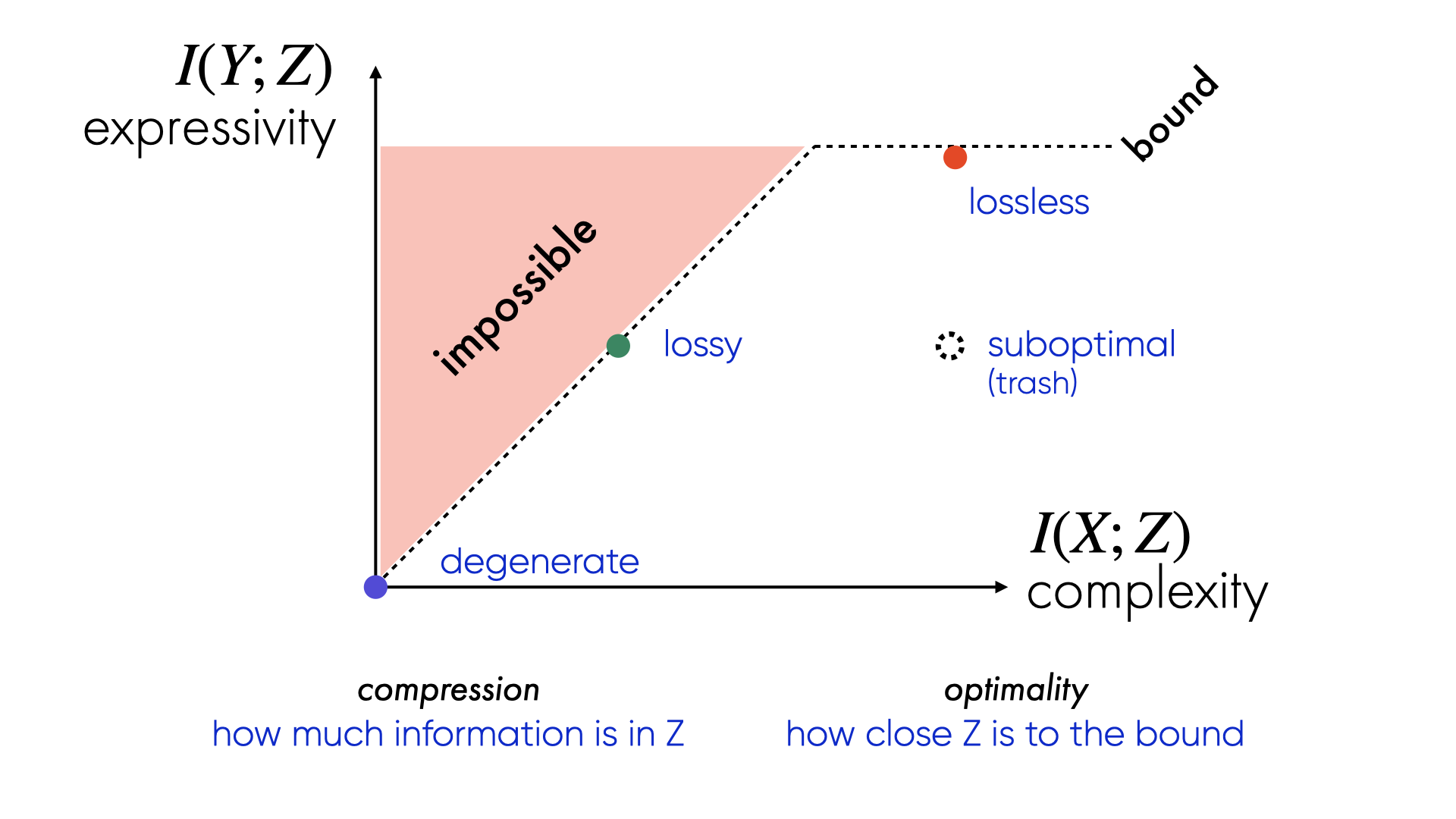
the information bottleneck bound is the frontier — the maximum expressivity achievable at a given complexity. lossless sits at the far right: maximum complexity, maximum expressivity. good lossy compression trades complexity while staying close to the bound. suboptimal compression falls below it — throwing away information that was actually useful.
the goal, for any compression scheme, is to sit on the bound. as discussed above this is in part because compression is about generalisation, and the geometry of the compressed space. more compression - while maintaining the level of target information - means more abstraction, stronger similarity structures, and more robust generalisation.
what is the source distribution?
now, consider a language model.
every compression scheme is designed around a source distribution — the space of things it expects to compress. mp3 is designed around the space of audio signals that humans actually produce and care about: music, speech, ambient sound in the range of human hearing. jpeg is designed around the space of natural images. the codec only works well when the input actually comes from that distribution.
this matters because the source distribution defines what “faithful reconstruction” even means. an mp3 of a dog whistle would likely discard the only information in the signal. the codec was designed for a different source.
for large language models, the question of what the source distribution is turns out to be surprisingly slippery. the obvious answer is: the internet. that’s where the vast majority of the training data comes from. but the internet is itself a biased, noisy sample of something else — human language? human knowledge in toto? maybe the full distribution of things humans think and write and argue about? but even then the internet over-represents certain languages, certain communities, certain topics, certain time periods. so it can’t be the true distribution of human language or knoweldge, at best a biased sample from it.
so an llm is a lossy compression of a biased sample of human language — which is itself a partial, noisy channel for human knowledge and thought. there are at least two layers of compression before you even get to the model: the mapping from “everything humans know and think” to “what ends up written on the internet,” and the mapping from the internet to the training data the model actually sees.
llms as lossy compression
a large language model takes trillions of tokens of text and compresses them into billions of floating-point weights. that’s a dramatic reduction. the model can’t store everything it saw verbatim — there isn’t space. it has to forget.
the training objective — predicting the next token — acts as the codec. it defines what “distortion” means: information is worth keeping if it helps predict what comes next in human-generated text. structure that’s useful for that task gets preserved. structure that isn’t gets discarded.
what this produces is a compressed space with similarity structure. words, concepts, facts, reasoning patterns that play similar roles in predicting text end up close together in the model’s representations. the compression has organised the model’s knowledge by what’s functionally equivalent, not by what’s lexically similar.
and that’s why llms can generalise. they can handle prompts they’ve never seen before because those prompts land somewhere in a compressed space where nearby points already have sensible outputs. the model isn’t retrieving an exact memory — it’s interpolating from structure, exactly as you’d expect from a well-designed lossy codec.
the right question to ask about an llm isn’t “did it memorise this fact?” it’s “did the compression preserve the right structure?” a good compression — one that sits close to the information bottleneck bound — should let you recognizably recover the shape of the internet it was trained on, even if some bits are discarded in the process.
post-training changes the codec. when a model is fine-tuned on human preference data (Bai et al. 2022) — through reinforcement learning from human feedback or direct preference optimisation — the objective shifts from “predict the next token” to “produce responses humans prefer.” in the information bottleneck framing, the target variable Y changes. what counts as distortion changes with it. the compression is now organised around preference rather than prediction: information relevant to what humans find helpful, accurate, or safe gets preserved and sharpened; information relevant only to raw text continuation gets pushed out. the compressed space reorganises — same weights, different geometry. this is why post-training can feel like a different model: the similarity structure has been redrawn around a different task.
whether our current models actually achieve that — how close to the bound they are, what information survives and what doesn’t, whether the structure they preserve predicts their capabilities — that’s what our ICLR 2026 paper is about.
how is this different from other work interpreting llms?
A hallmark of large-scale distributed systems, like neural networks, is that they are difficult to understand as a function of their parts alone (Anderson 1972). Despite this most interpretability tries to understand the role of individual heads, or layers, or subspaces.
Here we give an account of an entire LLM as a lossy compression, and show how doing so lets us understand pre-training dynamics, the effects of scale, and why some models are better than others.